jpa.01
엔티티 매니저와 영속성 컨텍스트

spring을 이용해서 웹 서버를 개발하다보면, persistence framework로 주로 JPA를 사용하곤 합니다.
프로젝트에서 jpa를 사용해보며 기본적인 데이터 crud 처리에 익숙해졌지만, 커넥션 관리, 트랜잭션 처리 같은
내부 동작에 대해서 알아보기 위해 포스팅을 작성하게 됐습니다.
jpa는 어떤 기능을 제공하는 API일까
spring boot를 이용해 웹 서버를 개발할 때, spring data jpa를 사용해 아주 간편하게 데이터 crud 작업을 처리했습니다.
1
interface MemberRepository extends JpaRepository<Member, Long> {}
위와 같이 인터페이스를 정의하는 것만으로도 데이터 저장, 조회, 삭제 작업을 처리할 수 있습니다.
spring data jpa는 jpa 기반 repository를 spring 애플리케이션에서 사용하기 편리하게 만들어주는 프레임워크입니다.
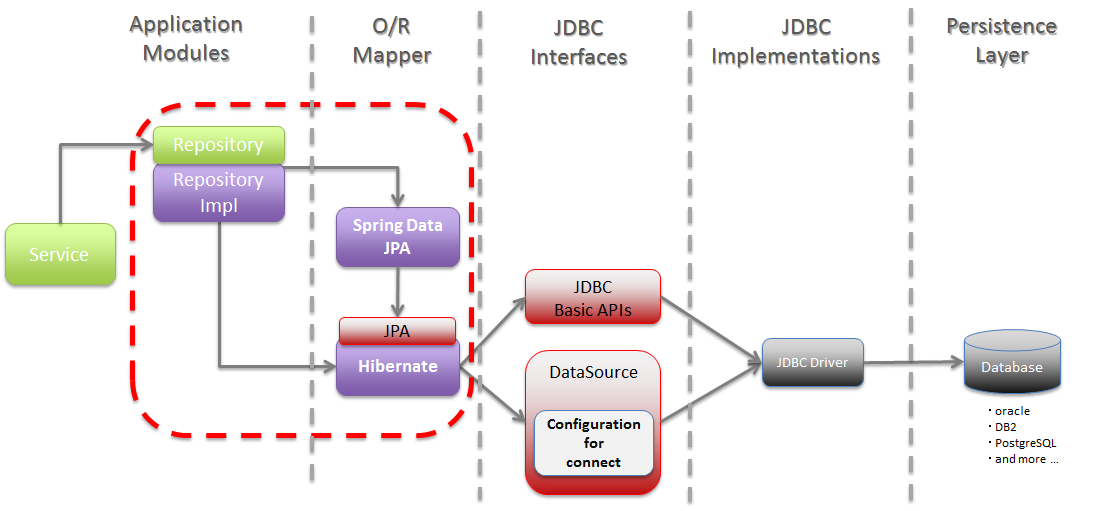
jpa가 직접 db에 접근하는 기능을 제공하는 api는 아니기에 실제 데이터베이스 접근은 jdbc api를 통해 이루어집니다.
하지만 jdbc만을 이용해서 데이터베이스 접근 작업들을 처리하기에는 몇몇 문제점들이 존재합니다.
우선 jdbc만을 사용하면 수 많은 반복 코드를 작성해야합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class InsertTest {
public static void main(String[] args) {
// pet 테이블에는 이름/소유자/종/성별/출생일 칼럼이 있습니다.
insert("봄이", "victolee", "페르시안", "m", "2010-08-21", null);
}
public static void insert(String name, String owner, String species,
String gender, String birth, String death){
Connection conn = null;
PreparedStatement pstmt = null;
try{
// 1. 드라이버 로딩
Class.forName("com.mysql.jdbc.Driver");
// 2. 연결하기
String url = "jdbc:mysql://localhost/dev";
conn = DriverManager.getConnection(url, "dev", "dev");
// 3. SQL 쿼리 준비
// 추가하려는 데이터의 값은 전달된 인자를 통해 동적으로 할당되는 값이다.
// 즉 어떤 값이 전달될지 모르므로 Select 할 때와 달리
// stmt = conn.createStatement(); 를 작성하지 않고
// pstmt = conn.prepareStatement(sql); 로 작성하여 데이터를 추가할 것임을 알립니다.
// 물론 sql 쿼리 내에서 + 연산자로 한 줄로 작성할 수 있지만 가독성이 너무 떨어지게 되므로
// 이 방법을 권합니다.
String sql = "INSERT INTO pet VALUES (?,?,?,?,?,?)";
pstmt = conn.prepareStatement(sql);
// 4. 데이터 binding
pstmt.setString(1, name);
pstmt.setString(2, owner);
pstmt.setString(3, species);
pstmt.setString(4, gender);
pstmt.setString(5, birth);
pstmt.setString(6, death);
// 5. 쿼리 실행 및 결과 처리
// SELECT와 달리 INSERT는 반환되는 데이터들이 없으므로
// ResultSet 객체가 필요 없고, 바로 pstmt.executeUpdate()메서드를 호출하면 됩니다.
// INSERT, UPDATE, DELETE 쿼리는 이와 같이 메서드를 호출하며
// SELECT에서는 stmt.executeQuery(sql); 메서드를 사용했었습니다.
// @return int - 몇 개의 row가 영향을 미쳤는지를 반환
int count = pstmt.executeUpdate();
if( count == 0 ){
System.out.println("데이터 입력 실패");
}
else{
System.out.println("데이터 입력 성공");
}
}
catch( ClassNotFoundException e){
System.out.println("드라이버 로딩 실패");
}
catch( SQLException e){
System.out.println("에러 " + e);
}
finally{
try{
if( conn != null && !conn.isClosed()){
conn.close();
}
if( pstmt != null && !pstmt.isClosed()){
pstmt.close();
}
}
catch( SQLException e){
e.printStackTrace();
}
}
}
}
// 출처 https://devlog-wjdrbs96.tistory.com/139
간단한 데이터 저장 코드를 jdbc만을 이용해서 작성하려면 위와 같이 수 많은 코드를 작성해야합니다.
그렇기에 jpa를 사용해서 반복적인 코드 작성을 줄일 수 있고, 엔티티 중심 코드를 작성할 수 있습니다.
jpa를 사용한 간단한 예제 코드
jpa를 사용하면 다음과 같이 데이터 crud 처리를 할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
import jakarta.persistence.EntityManager
import model.Member
class Application
fun main() {
val emf = jakarta.persistence.Persistence.createEntityManagerFactory("model")
val entityManager = emf.createEntityManager()
val transaction = entityManager.transaction
try {
transaction.begin()
logic(entityManager)
transaction.commit()
} catch (ex: Exception) {
ex.printStackTrace()
transaction.rollback()
} finally {
entityManager.close()
emf.close()
}
}
fun logic(em: EntityManager) {
println("performing business logic")
val member = Member("id", "newMember", 25)
// 데이터 저장
em.persist(member)
member.age = 26
// 데이터 조회
val find = em.find(Member::class.java, "id")
val members = em.createQuery("select m from Member m", Member::class.java).resultList
// 데이터 삭제
em.remove(member)
}
위 코드를 살펴보면, 3부분으로 나눌 수 있습니다.
- 엔티티 매니저 설정
- 엔티티 매니저 팩토리에서 엔티티 매니저를 생성합니다.
- 엔티티 매니저를 사용해서 엔티티를 데이터베이스에 등록, 수정, 삭제, 조회할 수 있습니다.
- 트랜잭션 관리
- jpa를 사용하면 항상 트랜잭션 안에서 데이터를 변경해야 합니다.
- 트랜잭션 없이 데이터를 변경하면 에러가 발생합니다.
- 비즈니스 로직
엔티티 매니저 팩토리와 엔티티 매니저
데이터베이스를 하나만 사용하는 애플리케이션은 일반적으로 엔티티 매니저 팩토리를 하나만 생성합니다.
엔티티 매니저 팩토리를 생성할 때 데이터베이스 커넥션 풀도 함께 생성하기에 생성 비용이 매우 큽니다.
그렇기에 애플리케이션 전체에서 공유하도록 설계되었습니다.
 엔티티 매니저 팩토리에서 엔티티 매니저를 생성하는 비용은 거의 들지 않기에, 스레드 별로 엔티티 매니저를 사용하는 것이 권장됩니다. 그리고 엔티티 매니저는 데이터베이스 연결이 필요한 시점에 커넥션을 획득합니다.
엔티티 매니저 팩토리에서 엔티티 매니저를 생성하는 비용은 거의 들지 않기에, 스레드 별로 엔티티 매니저를 사용하는 것이 권장됩니다. 그리고 엔티티 매니저는 데이터베이스 연결이 필요한 시점에 커넥션을 획득합니다.
영속성 컨텍스트
엔티티 매니저로 엔티티를 저장하거나 조회하면 엔티티 매니저는 영속성 컨텍스트에 엔티티를 보관합니다. 영속성 컨텍스트는 엔티티 매니저를 생성할 때 하나 만들어집니다. 그리고 엔티티 매니저를 통해서 영속성 컨텍스트에 접근할 수 있고, 영속성 컨텍스트를 관리할 수 있습니다.
엔티티 생명 주기
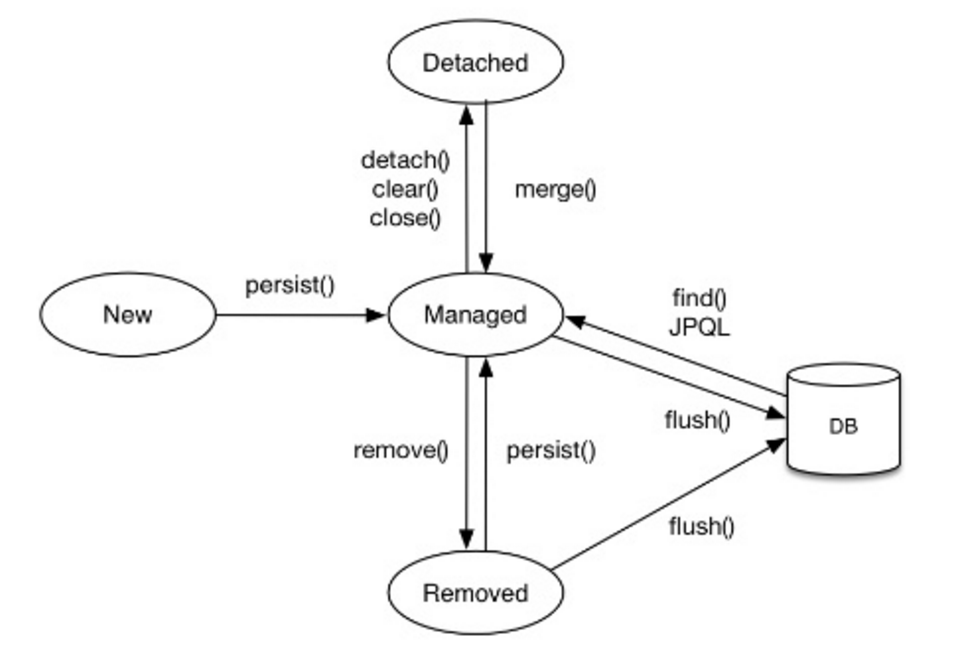
엔티티에는 4가지 상태가 존재합니다.
- 비영속 : 영속성 컨텍스트와 전혀 관계가 없는 상태
- 영속 : 영속성 컨텍스트에 저장된 상태
- 준영속 : 영속성 컨텍스트에 저장되었다가 분리된 상태
- 삭제 : 삭제된 상태
영속성 컨텍스트의 특징은 다음과 같습니다.
- 식별자 값
- 영속 상태 엔티티는 반드시 식별자 값이 있어야 합니다.
- 데이터베이스 저장
- 트랜잭션을 커밋하는 순간 영속성 컨텍스트에 새로 저장된 엔티티를 데이터베이스에 반영하고 이것을 flush라고 합니다.
- 1차 캐시
- 영속 상태의 엔티티는 모두 영속성 컨텍스트 내부 1차 캐시에 저장됩니다.
em.find()로 엔티티를 조회할 때, 1차 캐시에 엔티티가 존재하면, 1차 캐시에서 엔티티를 조회합니다.- 1차 캐시에 엔티티가 존재하지 않는다면, 1차 캐시에 저장한 후에 영속 상태의 엔티티를 반환합니다.
- 쓰기 지연
em.persist()를 호출하는 순간, insert sql이 곧 바로 실행되지는 않습니다.- 엔티티 매니저는 트랜잭션을 커밋하기 전까지 데이터베이스에 엔티티를 저장하지 않고, 내부 쿼리 저장소에 insert sql을 쌓아둡니다.
- 그리고 트랜잭션을 커밋할 때 모아둔 쿼리를 데이터베이스에 보냅니다.
- 변경 감지
- 영속 상태의 엔티티의 값을 변경하면, jpa는 엔티티 변경 사항을 자동으로 데이터베이스에 반영합니다.
- 엔티티를 영속성 컨텍스트에 등록할 때, 최초 상태의 스냅샷을 저장하고
flush시점에 스냅샷과 엔티티의 상태를 비교해서 update 쿼리를 쓰기 지연 저장소에 보냅니다.
- 엔티티 삭제
em.remove()를 호출하면, 영속성 컨텍스트에서 해당 엔티티를 제거하고, delete 쿼리를 쓰기 지연 저장소에 보냅니다.
flush
flush는 영속성 컨텍스트의 변경 내용을 데이터베이스에 반영합니다. flush가 실행되면, 변경 감지가 동작해서 영속성 컨텍스트에 있는 모든 엔티티를 스냅샷과 비교해서 수정된 엔티티를 찾고, 수정된 엔티티의 수정 쿼리를 작성해 쓰기 지연 저장소에 등록합니다. 그 이후에 쓰기 지연 SQL 저장소의 쿼리를 데이터베이스에 전송합니다.
영속성 컨텍스트를 flush하는 방법은 3가지가 존재합니다.
- 직접 호출
em.flush()메소드를 호출해서 강제로 flush합니다.
- 트랜잭션 커밋시 자동 호출
- 트랜잭션을 커밋하기 전에 flush를 호출해서 영속성 컨텍스트의 변경 내용을 데이터베이스에 반영합니다.
- JPQL 쿼리 실행시
- jpql는 sql로 변환되어 실행되기에 영속성 컨텍스트의 변경 내용을 데이터베이스에 반영하기 위해 자동으로 실행됩니다.
준영속
엔티티가 영속성 컨텍스트에서 분리된 것을 준영속 상태라 합니다. 준영속 상태의 엔티티는 영속성 컨텍스트가 제공하는 기능을 사용할 수 없습니다.
영속 상태의 엔티티를 준영속 상태로 만드는 방법은 3가지입니다.
- em.detach() : 특정 엔티티만 준영속 상태로 전환합니다.
- em.clear() : 영속성 컨텍스트를 완전히 초기화합니다.
- em.close() : 영속성 컨텍스트를 종료합니다.
엔티티가 준영속 상태가 되면, 1차 캐시에서 엔티티가 제거되고, 쓰기 지연 저장소에 있는 엔티티 관련 쿼리들도 제거됩니다.
준영속 상태의 엔티티를 다시 영속 상태로 변경하려면 merge()를 호출하면 됩니다.
merge()는 영속 상태의 새로운 엔티티를 반환합니다.
비영속 상태의 엔티티도 영속 상태로 만들 수 있습니다. 파라미터로 넘어온 엔티티의 식별자 값으로 영속성 컨텍스트를 조회하고 찾는 엔티티가 없으면 데이터베이스에서 조회합니다. 데이터베이스에서도 발견하지 못하면 새로운 엔티티를 생성해서 병합합니다.
참고 블로그 링크
https://gmlwjd9405.github.io/2018/12/25/difference-jdbc-jpa-mybatis.html
https://gmlwjd9405.github.io/2018/05/15/setting-for-db-programming.html
https://devlog-wjdrbs96.tistory.com/139