mysql group replication.01
mysql group replication 에 대하여

Group Replication의 배경
MySQL group replication을 사용해서 탄력적이고, 고가용성, replication 구성을 만들 수 있습니다.
Group은 single primary node로 한 서버만 수정 요청을 허용하게 구성할 수도 있고, multi primary node로 모든 서버가 수정되게 허용할 수도 있습니다.
내장된 그룹 멤버쉽 서비스가 모든 서버가 언제든지 일관된 그룹 뷰를 사용할 수 있도록 합니다. 서버는 그룹에 가입하거나 떠날 수 있으며, 이에 따라 뷰가 업데이트됩니다. 때때로 서버가 예기치 않게 그룹을 떠날 수도 있는데, 이 경우에는 장애 감지 메커니즘이 이를 감지하고 뷰가 변경되었음을 알립니다. 이 모든 과정은 자동으로 이뤄집니다.
Group Replication은 데이터베이스 서비스의 지속적 가용성을 보장합니다. 그러나 그룹의 구성원 중 하나가 사용 불가능해지면, 해당 그룹 구성원에 연결된 클라이언트의 일종을 사용하여 그룹 내 다른 서버로 리다이렉션하거나 failover 처리를 해야합니다.
MySQL Router가 이런 작업을 처리할 수 있습니다.
replication technologies
전통적인 MySQL replication은 Source에서 Replica으로의 간단한 복제 방식을 제공합니다. Source는 primary이고, 하나 이상의 secondary Replica들아 존재합니다.
Source가 트랜잭션을 적용하고, 커밋하면, 비동기적으로 replica들에게 전파되어 statement-based replication에서는 트랜잭션을 다시 실행하거나, row-based replication에서는 곧바로 적용합니다. 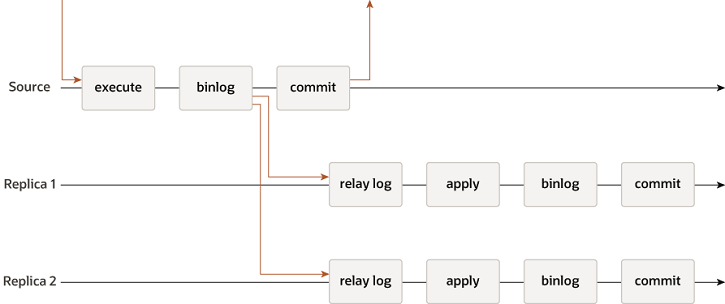
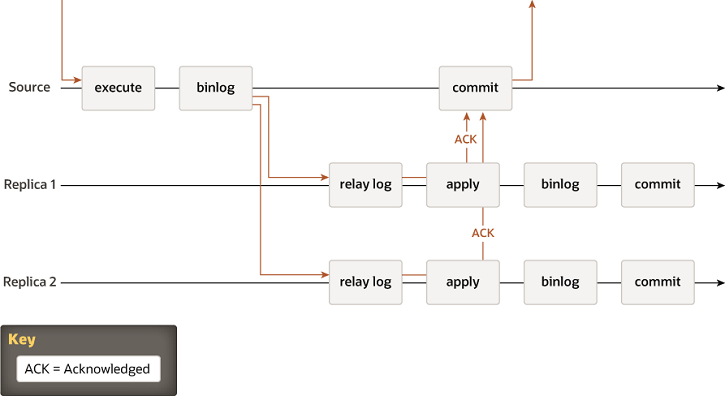
semi-synchronous 복제 기법도 존재합니다. primary는 secondary들이 모두 트랜잭션의 실생을 종료할 때까지 대기하고 커밋합니다.
Group replication
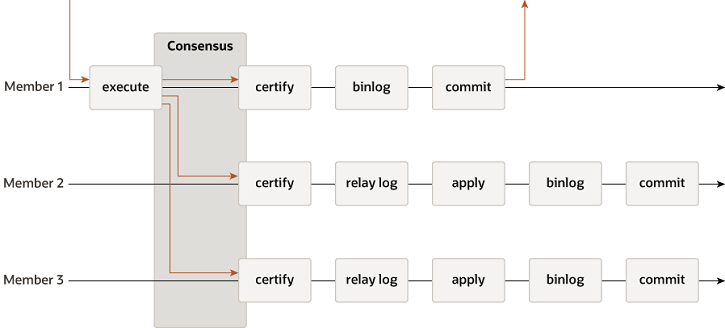
그룹 레플리케이션은 fault-tolerant 시스템을 구현하기 위한 기술입니다. 레플리케이션 그룹은 서버들의 집합으로, 각 서버는 데이터에 대한 완전한 복제본을 가지고 있습니다. 그리고 서버끼리는 메세지 패싱을 통해 상호작용합니다. 그룹 레플리케이션의 커뮤니케이션 레이어는 atomic message나 total order message delivery같은 일련의 보증을 제공합니다. 이러한 강력한 속성들은 더 유용한 추상화를 제공하며, 이를 통해 더 고도화된 데이터베이스 복제 솔루션을 구축하는 데 활용할 수 있습니다.
MySQL 그룹 레플리케이션은 이러한 속성과 추상화를 기반으로 다중 소스 업데이트 방식의 복제 프로토콜을 구현합니다. 이를 통해 모든 노드에서 데이터 업데이트가 가능합니다. 레플리케이션 그룹은 각각 독립적으로 트랜잭션을 실행할 수 있는 다수의 서버로 구성됩니다. 읽기/쓰기 트랜잭션은 그룹에 의해서 승인된 이후 커밋 가능합니다. 달리 말하면, 읽기/쓰기 트랜잭션의 경우 그룹 전체가 해당 트랜잭션을 커밋할지 여부를 결정해야 하며, 커밋은 트랜잭션을 시작한 서버의 일방적인 결정이 아닙니다. 반면 읽기 전용 트랜잭션은 그룹 내에서 조정이 필요하지 않으며 즉시 커밋됩니다.
읽기/쓰기 트랜잭션이 커밋할 준비가 완료되면, 서버는 원자적으로 변경된 행과 그에 대응되는 고유 식별자를 브로드캐스트합니다. 트랜잭션이 원자적으로 브로드캐스트 되기에, 모든 서버는 트랜잭션을 받거나 받지 못합니다. 만약 받았다면, 모두 같은 순서로 트랜잭션을 받게됩니다. 결과적으로 모든 서버는 같은 트랜잭션을 같은 순서로 받기에, 그룹간 트랜잭션에 대한 전역적인 총 순서가 확립됩니다.
하지만 서로 다른 서버에서 실행되는 트랜잭션들은 충돌할 수 있습니다. 이런 충돌들은 서로 다른 동시에 진행되는 트랜잭션들의 변경하는 데이터의 고유 식별자를 비교하는 것으로 감지 가능하고, 이런 프로세스를 certification이라 합니다. certification 중 row-level로 충돌 감지가 진행됩니다. 서로 다른 트랜잭션이 동시에 같은 row를 변경한다면 충돌이 발생합니다. 충돌 해결 과정은 먼저 발생한 트랜잭션이 모든 서버에 커밋되고, 이후 발생한 트랜잭션은 중단되어 시작 서버에서 롤백되며, 그룹의 다른 서버에서는 삭제됩니다.
인증된 트랜잭션을 적용하고, 외부화하기 위해서 그룹 레플리케이션은 일관성과 유효성을 깨뜨리지 않는 한 서버가 합의된 트랜잭션 순서에서 벗어나는 것을 허용합니다. 그룹 복제는 eventual consistency system으로 수신 트래픽이 느려지거나 멈추면 모든 그룹 구성원이 동일한 데이터 내용을 가지게 됩니다. 트래픽이 계속 발생하는 동안, 트랜잭션은 살짝 다른 순서로 외부화될 수 있습니다.
multi-primary node의 경우, 로컬 트랜잭션은 인증 과정을 거친 이후 바로 외부화될 수 있습니다. 이때, 이전의 발생한 원격 트랜잭션이 반영되지 않은 상태일 수 있습니다. 인증 프로세스가 트랜잭션간 충돌이 없다고 판단할 때, 이런 결과가 발생할 수 있습니다.
single-primary node의 경우, primary 서버가 위와 같이 동작할 가능성은 낮지만, secondary 서버들은 항상 합의된 순서로 커밋되고 외부화됩니다.
multi-primary and single-primary modes
그룹 레플리케이션은 single-primary 혹은 multi-primary로 동작합니다. 그룹의 모드는 group_replication_single_primary_mode 시스템 변수를 이용해 명시할 수 있습니다. 그룹의 모든 멤버가 동일한 값을 가져야합니다. ON 값은 단일 primary란 의미이고, 기본 값입니다. OFF 값은 mutli primary란 의미입니다.
group_replication_single_primary_mode값을 실행중일 때 변경할 수는 없습니다. Group replication이 실행 중일 때group_replication_switch_to_single_primary_mode()혹은group_replication_switch_to_multi_primary_mode()함수를 사용해서 모드를 변경해야합니다.배포 모드와는 무관하게, 그룹 레플리케이션 자체만으로는 client-side failover를 제공하지 않습니다. MySQL Router를 사용해서 이런 작업을 처리해야합니다.
Single Primary Mode
단일 프라이머리 모드에서 그룹은 read/write 모드로 설정된 하나의 프라이머리 서버를 가집니다. 그룹의 다른 모든 멤버들은 read_only 모드로(super_read_only=ON)으로 설정됩니다. 프라이머리 서버가 주로 전체 그룹을 bootstrap합니다. 그룹에 참여하는 모든 다른 서버들은 프라이머리 서버에대한 정보를 알고, 자동으로 read_only 모드로 설정됩니다.
단일 프라이머리 모드에서, 그룹 레플리케이션은 하나의 서버만 쓰기 작업을 처리하기에, 멀티 프라어머리 모드와 비교해서, 일관성 확인 작업이 덜 촘촘해도됩니다. group_replication_enforce_update_everywhere_checks 옵션을 이용해 강한 일관성 체크를 할지를 설정할 수 있습니다. 단일 프라이머리 모드에서 배포하거나, 그룹의 상태를 단일 프라이머리로 변경할 때, 이 옵션은 OFF로 설정되야합니다.
프라이머리 서버로 선정된 멤버는 다음과 같은 방법으로 변경될 수 있습니다.
- 기존 프라이머리가 자발적으로 혹은, 불가피하게 그룹을 떠날 경우, 새로운 프라이머리가 선정됩니다.
group_replication_set_as_primary()함수를 이용해서 새로운 primary를 지정했을 때group_replication_switch_to_single_primary_mode()함수를 이용해서 단일 프라이머리 모드로 전환했을 때
새로운 프라이머리 선정 과정은 다음과 같습니다.
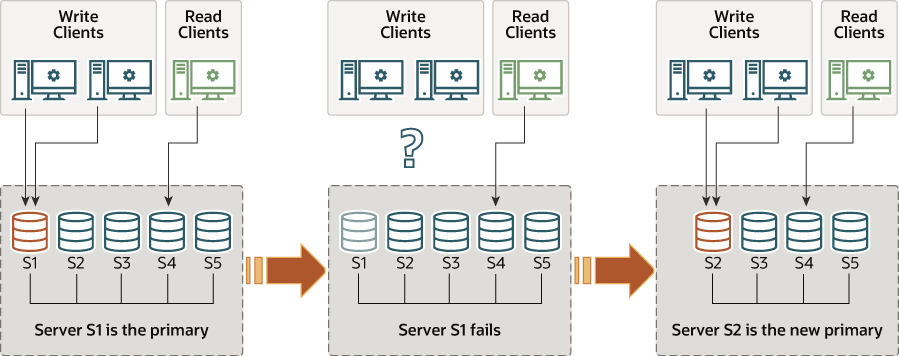
새로운 프라이머리가 선택될 때, 이전 프라이머리에서 적용된 변경 사항 중 아직 새로운 프라이머리에 적용되지 않은 변경 사항이 있을 수도 있습니다. 이런 경우에 새로운 프라이머리가 변경 사항을 따라잡을 때 까지 읽기/쓰기 트랜잭션은 충돌이 발생하고 롤백될 수도 있습니다. 그룹 레플리케이션 flow control 메커니즘은 이런 멤버간 속도 차이를 최소화하고, flow control이 활성화되고 적절하게 조율되면 이런 문제 상황의 발생을 줄일 수 있습니다.
Flow control에서 flow control 관련한 정보들을 확인할 수 있습니다.
group_replication_consistency시스템 변수를 사용해서 그룹의 일관성 레벨을 설정해서 이런 이슈를 방지할 수도 있습니다.BEFORE_ON_PRIMARY_FAILOVER(기본값입니다.) 혹은 이것보다 상위 일관성 레벨은 새로운 프라이머리에 옛 변경 사항들이 먼저 처리되도록합니다.Transaction Consistency Guarantees에서 트랜잭션 일관성에 대해 추가적인 정보를 확인할 수 있습니다.
Primary election algorithm
자동으로 새로운 프라이머리 멤버를 선정하는 것은 그룹에 속한 멤버 중 가장 프라이머리로 적합한 멤버를 고르는 과정을 포함합니다. 각 멤버는 MySQL 서버에서 제공하는 프라이머리 선정 알고리즘을 통해 각자 새로운 프라이머리를 결정합니다. 모든 멤버들이 같은 멤버를 선정해야되기에, 그룹에 속한 멤버 중 MySQL 버전이 가장 낮은 멤버의 알고리즘을 사용해서 멤버를 선정합니다.
프라이머리를 선정하는 기준은 다음과 같은 순으로 선정됩니다.
- 멤버 중 어느 멤버가 가장 낮은 MySQL 버전을 실행하는지 확인합니다. 모든 그룹 멤버는 버전 순으로 정렬됩니다.
- 하나 이상의 멤버가 가장 낮은 MySQL 버전으로 실행중이라면,
group_replication_member_weight시스템 변수 값을 확인합니다. 이 시스템 변수는 0부터 100까지의 값을 가질 수 있습니다. 모든 멤버는 기본적으로 50의 값을 가집니다. 50보다 작은 값을 가지면 순위는 낮아지고 큰 값을 가지면 순위는 높아집니다. 이 값을 이용해서 더 나은 하드웨어를 가진 멤버가 우선적으로 선정되게 지정할 수 있습니다. - 가중치 값까지 같다면 최종적으로
server_uuid시스템 변수 값으로 선정됩니다. 가장 작은server_uuid값을 가진 멤버가 프라이머리로 선정됩니다.
finding the primary
performance_schema.replication_group_members테이블의 MEMBER_ROLE 컬럼을 확인하는 것으로 어느 멤버가 프라이머리인지 확인할 수 있습니다.
1
2
3
4
5
6
7
8
mysql> SELECT MEMBER_HOST, MEMBER_ROLE FROM performance_schema.replication_group_members;
+-------------------------+-------------+
| MEMBER_HOST | MEMBER_ROLE |
+-------------------------+-------------+
| remote1.example.com | PRIMARY |
| remote2.example.com | SECONDARY |
| remote3.example.com | SECONDARY |
+-------------------------+-------------+
Deploying Group Replication in Single-Primary Mode
먼저 최소 3개의 MySQL 서버를 배포해야합니다. 그리고 Group Replication 플러그인은 8.4 버전부터 지원되기에, 8.4 버전 이상을 사용해야합니다.
Storage Engines
Group Replication을 위해서는 데이터는 InnoDB transactional storage engine에 저장되야합니다. 다른 저장소는 Group Replication 에러를 발생할 수 있기에 사용되선 안됩니다. disabled_storage_engines 시스템 변수를 다음과 같이 설정해서 다른 스토리지 엔진의 사용을 막아야합니다.
1
disabled_storage_engines="MyISAM,BLACKHOLE,FEDERATED,ARCHIVE,MEMORY"
Replication Framework
다음 설정은 MySQL Group Replication의 요구사항을 설정합니다.
1
2
3
server_id = 1
gtid_mode=ON // GTID = Global Transaction Identifier
enforce_gtid_consistency=ON
위 설정은 서버에 1이라는 식별자를 부여하고, GTID를 사용하여 안전하게 로그에 기록될 수 있는 명령문만 실행하도록 허용합니다. 이 설정은 기본적으로 활성화된 바이너리 로그에 기록된 이벤트의 체크섬을 비활성화합니다. MySQL 8.4의 그룹 복제(Group Replication)는 바이너리 로그에 있는 체크섬을 지원하며, 일부 채널에서 이벤트의 무결성을 확인하는 데 사용할 수 있습니다.
자세한 내용은 Group ReplicationLimitation에서 확인 가능합니다.
Group Replication Settings
다음 섹션은 서버의 Group Replication을 설정합니다.
1
2
3
4
5
6
plugin_load_add='group_replication.so'
group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
group_replication_start_on_boot=off
group_replication_local_address= "s1:33061"
group_replication_group_seeds= "s1:33061,s2:33061,s3:33061"
group_replication_bootstrap_group=off
plugin_load_add: Group Replication 플러그인을 추가합니다.group_relication_group_name: 조인하거나 생성할 그룹 명을 명시합니다.group_replication_group_name값은 유효한 UUID여야합니다.SELECT_UUID()함수를 이용해서 생성가능합니다. 이 UUID 그룹 구성원이 클라이언트로부터 받은 트랜잭션과 그룹 구성원 내부에서 생성된 뷰 변경 이벤트가 바이너리 로그에 기록될 때 사용되는 GTID의 일부를 형성합니다.group_replication_start_on_boot:off값으로 서버가 시작할 때 자동으로 오퍼레이션을 시작하지 말 것을 지정합니다. 이는 플러그인을 수동으로 시작하기 전에 서버를 구성할 수 있도록 보장하기 때문에 그룹 복제를 설정할 때 중요합니다. 멤버들을 설정한 이후에on값으로 설정해 서버가 시작하자마자 그룹 레플리케이션을 시작하게 설정할 수 있습니다.group_replication_local_address: 그룹 멤버가 다른 멤버와 내부 소통할 때 사용할 네트워크 주소와 포트를 지정합니다. 그룹 레플리케이션은 이 주소를 사용하여 그룹 통신 엔진(Xcom, Paxos 변형)의 원격 인스턴스 간의 내부 구성원 간 연결을 처리합니다.그룹 레플리케이션 로컬 주소는 SQL 클라이언트 커넥션에서 사용하는 호스트 명과 포트와는 달라야합니다. 그룹 레플리케이션 멤버들의 내부 소통에만 사용하는 호스트명과 주소를 명시해야합니다.
group_replication_local_address에 설정하는 네트워크 주소는 모든 그룹 멤버가 접근 가능해야합니다. 예를 들어 만약 서버 인스턴스가 다른 머신에서 실행되고 10.0.0.1 같은 고정된 아이피 주소를 가진다면, 그 값을 써도됩니다. 만약 포스트 명을 사용한다면, fully qualified name을 사용해야하고, DNS, 적절히 구서된 /etc/hosts 파일 또는 기타 이름 해석 프로세스를 통해 해당 이름이 해석 가능해야 합니다.group_replication_local_address에 권장되는 포트는 33061입니다.group_replication_local_address는 그룹 복제(Group Replication)에서 복제 그룹 내 구성원을 식별하는 고유 식별자로 사용됩니다. 호스트이름이나 IP주소가 모두 다르다면 모든 복제 그룹 구성원에게 동일한 포트를 사용할 수 있습니다.그룹 복제(Group Replication)의 분산 복구(distributed recovery) 과정에서 기존 구성원이 새로 합류하는 구성원에게 제공하는 연결은 group_replication_local_address에 설정된 네트워크 주소가 아닙니다. 그룹 구성원은 MySQL 서버의 호스트 이름과 포트로 지정된 표준 SQL 클라이언트 연결을 새로 합류하는 구성원에게 분산 복구용으로 제공합니다. 또한, 분산 복구를 위해 별도의 클라이언트 연결 목록을 제공할 수도 있습니다. 자세한 내용은 Connections for Distributed Recovery에 있습니다.
group_replication_group_seeds:group_replication_group_seeds를 사용해서 새로운 구성원이 그룹에 연결을 설정하는 데 사용하는 그룹 구성원의 호스트 이름과 포트를 설정할 수 있습니다. 이 구성원들을 seed members라고 부릅니다. 연결이 설정되면 그룹 멤버쉽 정도는 Performance Schema의replication_group_members테이블에 나열됩니다. 보통 group_replication_group_seeds 목록에는 각 그룹 구성원의 group_replication_local_address에 해당하는 호스트 이름과 포트가 포함되지만, 반드시 모든 구성원이 포함될 필요는 없으며 일부 구성원만 시드로 선택할 수 있습니다.group_replication_group_seeds에 리스트된hostname:port는group_replication_local_address로 설정한 멤버의 내부 소통 주소입니다.그룹을 시작하는 서버는 이 옵션을 사용하지 않습니다. 처음 시작하는 서버는 서버를 그룹으로 묶는 책임을 가집니다. 달리 말하면, 그룹을 묶는 서버가 가지고 있는 모든 데이터는 다음 참여할 멤버가 사용하게될 데이터가 됩니다. 그룹에 참여하는 2번째 서버는 그룹 내에 있는 유일한 서버에게 참여를 요청하고, 2번째 서버가 가지고 있지 않은 데이터는 복제됩니다.
다수의 서버를 한번에 참여시킬 때, 이미 기존에 참여한 멤버를 seed로 명시해야합니다. bootstrap 멤버를 먼저 실행하고 그 서버가 그룹을 만들게하는 것도 좋은 방법입니다. 그 후에 그 멤버를 seed member로 명시하면 나머지 멤버들이 조인하는 것을 보장합니다. 그룹을 만들면서 다수의 그룹 멤버가 동시에 조인하는 것은 지원되지 않습니다.
group_replication_bootstrap_group으로 그룹을 bootstrap할지말지를 설정합니다. s1이 그룹의 첫 번째 구성원임에도 옵션 파일에서 이 변수를 끄도록 설정합니다. 대신 인스턴스가 실행 중일 때group_replication_bootstrap_group을 구성하여 실제로 단 하나의 구성원만이 그룹을 bootstrap하도록 보장합니다.
User credentials for distributed recovery
group replication은 distributed recovery 프로세스를 사용해서 그룹에 멤버가 조인할 때, 그룹 멤버들을 동기화합니다. distributed recovery는 group_replication_recovery로 명명된 복제 채널을 이용해서 참여하는 멤버에서 바이너리 로그를 전달합니다. 그러므로 올바른 권한은 가진 복제 유저를 설정해서 group replication이 멤버간 복제 채널을 사용할 수 있게해야합니다. 보다 더 많은 정보는 Distributed Recovery에서 확인 가능합니다.
모든 그룹 멤버에 대해서 같은 복제 유저를 사용해야합니다. distributed recovery를 위해 복제 유저를 생성하는 과정은 바이너리 로그를 통해 확인할 수 있으며, distributed recovery로 하여금 이 구문을 복제해 유저를 생성할 것임을 신뢰해도됩니다. 혹은 바이너리 로깅을 복제 유저 생성 전에 해제하고, 수동으로 각 멤버를 생성할 수도 있습니다.
다른 서버로 변경사항이 전파되는 것을 막고 싶으면 이렇게 해도됩니다. 이렇게 설정하는 경우, 복제 유저 설정을 마치고, 바이너리 로깅을 다시 활성화해야합니다.
복제 유저 생성은 다음 과정을 통해 진행됩니다.
- MySQL 서버 인스턴스를 실행하고, 클라이언트를 연결합니다.
- 복제 유저를 인스턴스별로 설정하기 위해서 다음 구문을 실행합니다.
1
SET SQL_LOG_BIN=0;
- 다음 권한을 가진 MySQL 유저를 생성합니다.
REPLICATION SLAVE: distributed recovery가 데이터를 반환받기 위해서 필요합니다.CONNECTION_ADMIN: 서버 중 하나가 오프라인 모드로 전환되어도 Group Replication 커넥션을 종료하지 않기 위해 필요합니다.BACKUP_ADMIN: 그룹 서버들이 cloning을 지원한다면, distributed recovery가 cloning 작업을 수행하기 위해서 이 권한이 필요합니다.GROUP_REPLICATION_STREAM: MySQL communication stack이 그룹 내에서 사용된다면, 이 권한이 필요합니다.1 2 3 4 5 6
CREATE USER rpl_user@'%' IDENTIFIED BY 'password'; GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%'; GRANT CONNECTION_ADMIN on *.* TO rpl_user@'%'; GRANT BACKUP_ADMIN ON *.* TO rpl_user@'%'; GRANT GROUP_REPLICATION_STREAM ON *.* TO rpl_user@'%'; FLUSH PRIVILEGES;
- 앞서 바이너리 로그를 비활성했기에 다시 활성화합니다.
1
SET SQL_LOG_BIN=1;
- 복제 유저를 생성했으면, distributed recovery를 사용하기 위해서는 그 유저 정보를 제공해야합니다.
CHANGE REPLICATION SOURCE TO구문을 이용해서group_replication_recovery채널의 유저 정보를 세팅할 수 있습니다. 혹은START GROUP REPLICATION구문에 유저 정보를 명시할 수도 있습니다.CHANGE REPLICATION SOURCE TO구문으로 설정된 유저 정보는 서버의 replication metadata 레포지토리에 평문으로 저장됩니다. 그룹 레플리케이션이 시작될 때 적용됩니다.START GROUP REPLICATION으로 설정된 유저 정보는 메모리에만 존재되고,STOP GROUP REPLICATION구문 혹은 서버가 종료되면 사라집니다.1 2 3
CHANGE REPLICATION SOURCE TO SOURCE_USER='rpl_user', SOURCE_PASSWORD='password' FOR CHANNEL 'group_replication_recovery';
launching group replication
Group Replication 플러그인이 서버에 설치되어있는지 확인해야합니다. plugin_load_add='group_replication.so'를 옵션 파일에 작성했다면, 명시적으로 설치하지 않아도됩니다. 혹은 다음 명령어로 설치할 수 있습니다.
1
INSTALL PLUGIN group_replication SONAME 'group_replication.so'
Bootstrapping the group
그룹을 첫번째로 시작하는 것을 bootstrapping이라고 합니다. group_replication_bootstrap_group 시스템 변수로 그룹을 bootstrap할 수 있습니다. bootstrap은 하나의 서버에서 한번만 진행되야합니다. 만약 group_replication_bootstrap_group이 옵션 파일에 저장된다면, 서버를 재시작하게되면, 동일한 그룹 명을 가진 새로운 그룹이 만들어집니다. 그렇기에 성공적으로 그룹 bootstrap을 진행하기 위해서는 다음과 같이 진행해야 합니다.
1
2
3
SET GLOBAL group_replication_bootstrap_group=ON;
START GROUP_REPLICATION;
SET GLOBAL group_replication_bootstrap_group=OFF;
START GROUP REPLICATION 구문이 성공적으로 실행되면, 그룹은 한명의 멤버로 생성됩니다. 다음 구문을 통해 확인할 수 있습니다.
1
SELECT * FROM performance_schema.replication_group_members;
Adding instances to the group
추가할 서버 설정을 다음과 같이 구성합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
[mysqld]
#
# Disable other storage engines
#
disabled_storage_engines="MyISAM,BLACKHOLE,FEDERATED,ARCHIVE,MEMORY"
#
# Replication configuration parameters
#
server_id=2
gtid_mode=ON
enforce_gtid_consistency=ON
#
# Group Replication configuration
#
plugin_load_add='group_replication.so'
group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
group_replication_start_on_boot=off
group_replication_local_address= "s2:33061"
group_replication_group_seeds= "s1:33061,s2:33061,s3:33061"
group_replication_bootstrap_group= off
s1일때의 과정과 비슷하게 설정 파일을 작성했습니다. 그런 다음 distributed recovery 자격 증명을 다음과 같이 구성합니다. 서버 s1을 설정할 때 사용한 것과 동일하며, 사용자 자격 증명이 그룹 내에서 공유됩니다. 만약 distributed recovery를 통해 모든 구성원에서 사용자를 설정하려는 경우, s2가 시드 s1에 연결하면 복제 사용자가 s1로 복제되거나 클론됩니다.
만약 s1에서 사용자 자격 증명을 구성할 때 바이너리 로그가 활성화되지 않았거나 상태 전송을 위한 원격 클로닝 작업이 사용되지 않은 경우, s2에서 복제 사용자를 직접 생성해야 합니다. 이 경우, s2에 연결하여 다음 명령을 실행합니다.
1
2
3
4
5
6
7
8
SET SQL_LOG_BIN=0;
CREATE USER rpl_user@'%' IDENTIFIED BY 'password';
GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%';
GRANT CONNECTION_ADMIN ON *.* TO rpl_user@'%';
GRANT BACKUP_ADMIN ON *.* TO rpl_user@'%';
GRANT GRANT_REPLICATION_STREAM ON *.* TO rpl_user@'%';
FLUSH PRIVILEGES;
SET SQL_LOG_BIN=1;
CHANGE_REPLICATION_SOURCE_TO 를 이용해 사용자 정보를 지정하려면 다음과 같이 구문을 작성해야합니다.
1
2
CHANGE REPLICATION SOURCE TO SOURCE_USER='rpl_user', SOURCE_PASSWORD='password' \
FOR CHANNEL 'group_replication_recovery';
Group Replication 플러그인도 설치하고, START GROUP_REPLICATION명령어로 replication을 시작합니다.