Spring - Caching.7
hazelcast에 대하여
hazelcast 공식 문서를 참고하여 학습한 내용을 정리한 글입니다.
https://docs.hazelcast.org/docs/3.3/manual/html-single/hazelcast-documentation.html#hazelcast-overview
https://docs.hazelcast.com/imdg/4.2/
hazelcast
overview
hazelcast 공식 문서에서는 다음과 같이 hazelcast를 소개하고 있습니다.
Hazelcast는 오픈 소스 인메모리 데이터 그리드입니다. Java의 Map, Queue, ExecutorService, Lock 등 다양한 인터페이스의 분산 구현을 제공합니다. Hazelcast는 매우 가볍고 사용하기 쉽게 설계되었습니다. Hazelcast는 높은 확장성과 가용성을 자랑합니다. 분산 애플리케이션은 Hazelcast를 분산 캐싱, 동기화, 클러스터링, 처리, pub/sub 메시징 등에 사용할 수 있습니다. Hazelcast는 Java로 구현되었으며, Java, C/C++, .NET 및 REST용 클라이언트를 제공합니다. 또한 Hazelcast는 memcache 프로토콜도 지원합니다.
- Hazelcast는 간단합니다
- Hazelcast는 Java로 작성되었으며, 별도의 의존성이 없습니다. Java util 패키지의 동일한 API를 노출합니다. hazelcast.jar 의존성을 추가하고, 1분 이내에 JVM 클러스터링을 시작하여 확장 가능한 애플리케이션을 구축할 수 있습니다.
- Hazelcast는 피어 투 피어입니다
- 많은 NoSQL 솔루션과 달리 Hazelcast는 피어 투 피어 방식입니다. 마스터와 슬레이브가 없으며, 모든 노드는 동일한 양의 데이터를 저장하고 동일한 양의 처리를 수행합니다. Hazelcast는 기존 애플리케이션에 임베드되거나 클라이언트-서버 모드로 사용될 수 있으며, 이 경우 애플리케이션은 Hazelcast 노드에 클라이언트로 연결됩니다.
- Hazelcast는 확장 가능합니다
- Hazelcast는 수백, 수천 개의 노드로 확장하도록 설계되었습니다. 새 노드를 추가하면 자동으로 클러스터를 발견하고 메모리와 처리 용량이 선형적으로 증가합니다. 노드는 서로 간에 TCP 연결을 유지하며 모든 통신은 이 레이어를 통해 수행됩니다.
- Hazelcast는 빠릅니다
- Hazelcast는 모든 것을 인메모리에 저장합니다. 매우 빠른 읽기와 업데이트 성능을 발휘하도록 설계되었습니다.
- Hazelcast는 중복성을 가집니다
- Hazelcast는 각 데이터 항목의 백업을 여러 노드에 저장합니다. 노드 장애가 발생하면 백업에서 데이터를 복구하여 클러스터는 다운타임 없이 계속 작동합니다.
Hazelcast sharding
Hazelcast shard는 파티션입니다. 기본적으로 Hazelcast는 271개의 파티션을 가집니다. 파티션은 클러스터 멤버들에 균등하게 나눠집니다. 데이터의 중복 저장을 위해 backup 파티션도 균등하게 나눠서 저장합니다.
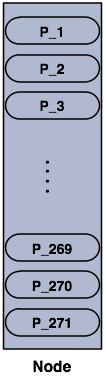
1개의 노드로 구성된 클러스터의 파티션입니다.
2개의 노드로 구성된 클러스터의 파티션입니다.
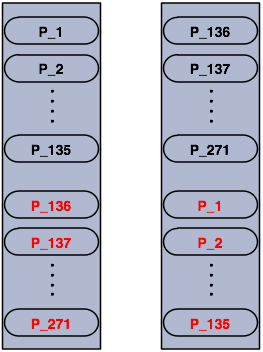
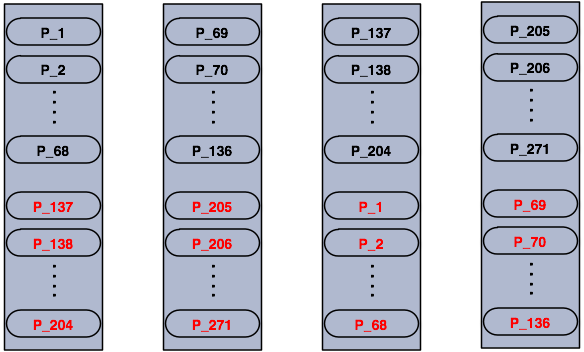
검정색 파티션이 primary 파티션이고, 빨간색 파티션은 백업 파티션입니다. 노드가 추가되면 파티션은 다음과 같은 구조로 균등하게 클러스터 멤버들에 분배됩니다.
Hazelcast Topology
Hazelcast 구성은 아래 사진처럼 임베디드 배포로 구성할 수 있습니다.
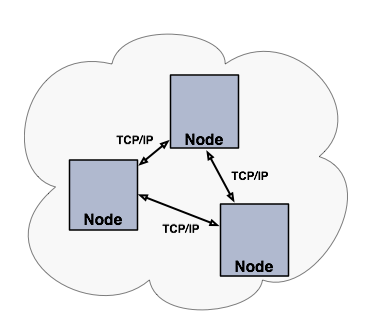
혹은 아래 사진처럼 서버 노드 클러스터를 독립적으로 생성하고 확장할 수 있습니다.
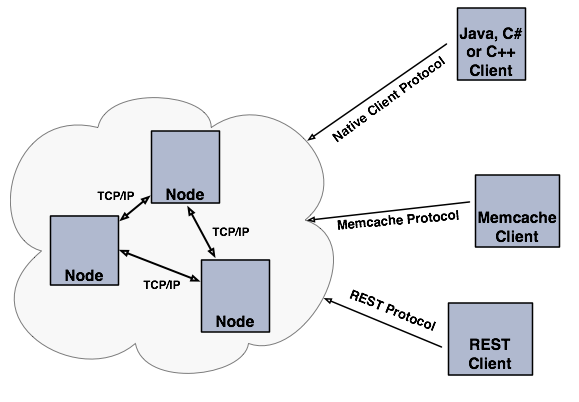
why hazelcast?
전통적인 방식의 데이터 저장
기본적으로 애플리케이션은 데이터베이스와 직접 통신하며 데이터를 읽고 쓰는 작업을 진행합니다. 이런 전통적인 아키텍처에서 성능을 향상시키기 위해서는 더 빠른 머신을 사용하거나 자원의 활용을 최적화해야하는데 이는 많은 비용이나 인력이 필요한 작업입니다.
이후 데이터베이스 데이터의 복사본을 유지하는 아이디어가 등장했습니다. 외부 key-value 저장소나 2차 캐싱 같은 기술을 사용하여 데이터베이스를 과도한 부하로부터 보호하였습니다. 그러나 데이터베이스가 포화상태이거나, 쓰기 작업이 주를 이룰 경우, 이런 접근 방식은 도움이 되지 않았습니다. 외부 저장소, 2차 캐싱 같은 기술은 조회 작업만 부하에서 격리하고, 조회 작업에서도 데이터 일관성 문제가 존재합니다. 데이터 일관성 문제에 대해서는 ttl, write through 같은 개념이 해결책으로 등장하였으나, ttl 캐시인 경우 항목 접근 빈도가 ttl보다 적으면 무용지물이고, write through는 클러스터에 여러 로컬 캐시가 있는 경우 캐시 간 일관성 문제가 발생합니다.
Hazelcast
Hazelcast는 데이터에 대한 완전히 새로운 접근 방식을 기반으로 설계되었으며, 분산 개념을 중심으로 이루어져 있습니다. 데이터는 유연성과 성능을 위해 클러스터 주위에 공유됩니다. Hazelcast는 클러스터링과 고도로 확장 가능한 데이터 분배를 위한 인메모리 데이터 그리드입니다.
Hazelcast의 주요 기능 중 하나는 마스터 노드가 없다는 것입니다. 클러스터의 각 노드는 기능적으로 동일하게 구성됩니다. 가장 오래된 노드가 클러스터 멤버를 관리하며, 데이터 할당을 자동으로 수행합니다.
또 다른 주요 기능은 데이터가 전적으로 인메모리에 지속된다는 것입니다. 이는 매우 빠릅니다. 노드 충돌과 같은 장애가 발생하더라도 Hazelcast는 클러스터의 모든 노드에 데이터를 복사하여 저장하므로 데이터 손실이 발생하지 않습니다.
Hazelcast 개요 섹션에 나와 있는 기능 목록에서 볼 수 있듯이, Hazelcast는 다수의 분산 컬렉션과 기능을 지원합니다. 다양한 소스로부터 다양한 구조로 데이터를 로드할 수 있으며, 메시지를 클러스터 전반에 걸쳐 전송할 수 있고, 동시 작업에 대비해 잠금을 설정할 수 있으며, 클러스터에서 발생하는 이벤트를 청취할 수 있습니다.
Hazelcast Strength
- Hazelcast 클러스터에는 “마스터” 노드가 존재하지 않습니다. 각 노드의 클러스터는 모두 동일하게 설정됩니다.
- 메모리에 저장하고 관리해야할 데이터의 크기가 커지면, 단순하게 클러스터에 노드를 추가하는 것으로 메모리 사이즈를 키울 수 있습니다.
- 데이터 뿐만 아니라 백업도 분산되어 관리되기에, 클러스터에 노드가 사라져도 데이터가 유실되지 않습니다.
- 전통적 key-value 솔루션과는 다르게 노드들은 서로 통신합니다.
hazelcast configuration
discovery mechanisms
Hazelcast 클러스터를 구성하기 위해서는 Hazelcast를 실행하는 멤버들을 클러스터로 묶어야합니다. Hazelcast는 다양한 클러스터링 매커니즘을 소개하는데, TCP/IP 매커니즘 설정에 대해서 간단하게 알아보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
hazelcast:
network:
join:
tcp-ip:
enabled: true
member-list:
- machine1
- machine2
- machine3:5799
- 192.168.1.0-7
- 192.168.1.21
위와 같이 클러스터할 전체 혹은 일부 서버의 도메인명이나 ip를 등록하는 것으로 클러스터링할 수 있습니다.
static VS dynamic configuration
Hazelcast 클러스터나 클라이언트는 static하게 혹은 dynamic하게 설정할 수 있습니다.
Hazelcast는 설정파일이나, Config 오브젝트를 이용해서 정적으로 설정할 수 있습니다.
이때 설정 우선순위는 다음과 같습니다.
동적인 설정은 Programmatic API, Management Center, REST 등과 같은 방법으로 설정 가능하고, 별도의 설정을 하지 않으면 동적으로 설정한 내용들은 클러스터 재시작시 사라집니다.
near cache
map entry 는 Hazelcast 클러스터에 파티션되어 저장됩니다. 특정 키를 자주 조회하는 상황에서, 해당 키가 다른 파티션에 위치한다면 매번 네트워크 비용이 발생하게 됩니다. 이런 경우에 near cache 도입을 고려해볼 수 있습니다. near cache를 사용하면 조회시 네트워크 비용이 발생하지 않는다는 장점이 있지만, 다음 같은 내용들을 고려해야합니다.
- JVM이 더 많은 데이터를 cache하기에 메모리를 더 많이 사용하게 됩니다.
- 만약 invalidation 설정이 되어 있을 때, 데이터가 자주 변경된다면 invalidation 처리 비용이 비쌉니다.
- near cache는 강한 데이터 일관성을 깰 수 있습니다.
near cache는 다음과 같이 설정할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
<near-cache>
<!--
Maximum size of the near cache. When max size is reached,
cache is evicted based on the policy defined.
Any integer between 0 and Integer.MAX_VALUE. 0 means
Integer.MAX_VALUE. Default is 0.
-->
<max-size>5000</max-size>
<!--
Maximum number of seconds for each entry to stay in the near cache. Entries that are
older than <time-to-live-seconds> will get automatically evicted from the near cache.
Any integer between 0 and Integer.MAX_VALUE. 0 means infinite. Default is 0.
-->
<time-to-live-seconds>0</time-to-live-seconds>
<!--
Maximum number of seconds each entry can stay in the near cache as untouched (not-read).
Entries that are not read (touched) more than <max-idle-seconds> value will get removed
from the near cache.
Any integer between 0 and Integer.MAX_VALUE. 0 means
Integer.MAX_VALUE. Default is 0.
-->
<max-idle-seconds>60</max-idle-seconds>
<!--
Valid values are:
NONE (no extra eviction, <time-to-live-seconds> may still apply),
LRU (Least Recently Used),
LFU (Least Frequently Used).
NONE is the default.
Regardless of the eviction policy used, <time-to-live-seconds> will still apply.
-->
<eviction-policy>LRU</eviction-policy>
<!--
Should the cached entries get evicted if the entries are changed (updated or removed).
true of false. Default is true.
-->
<invalidate-on-change>true</invalidate-on-change>
<!--
You may want also local entries to be cached.
This is useful when in memory format for near cache is different than the map's one.
By default it is disabled.
-->
<cache-local-entries>false</cache-local-entries>
</near-cache>
region factory
jpa와 함께 hazelcast를 사용할 때, region factory를 설정해야합니다. 사용할 수 있는 region factory는 두 종류가 있습니다.
HazelcastCacheRegionFactory
Hazelcast 표준 DistributedMap를 사용합니다. get, put, remove 같은 operation 들은 모두 DistributedMap 로직을 이용해 수행됩니다. HazelcastCacheRegionFactory의 유일한 단점은 HazelcastLocalCacheRegionFactory 와 비교했을 때 성능이 떨어진다는 점입니다. HazelcastCacheRegionFactory를 사용해서 다음 cache들을 사용할 수 있습니다.
- EntityCache
- CollectionCache
- TimeStampCache
HazelcastCacheRegionFactory를 사용하면 ManagementCenter를 통해 map를 확인할 수 있습니다.
HazelcastLocalCacheRegionFactory
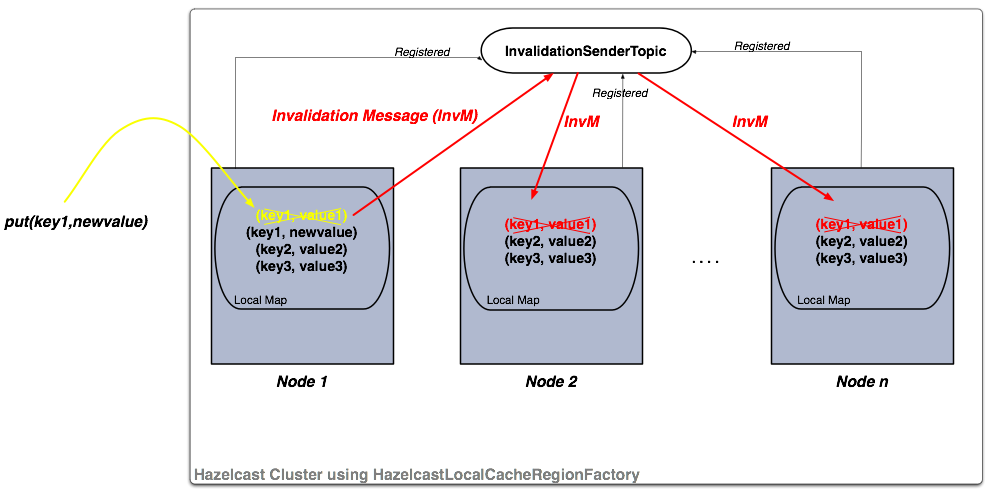
이 구조에서 각 클러스터 멤버들은 local map를 가지고, 각 map들은 HazelcastTopic에 등록되어있습니다. 멤버에서 put 혹은 remove 작업이 발생하면 토픽에 invalidation message가 생성되고 다른 멤버들에게 전달됩니다. 메세지를 전달받은 멤버들은 invalidation message에 전달된 키를 local map에서 삭제합니다. 해당 키 값에 대해 get 작업이 실행되면, 키 값은 새로운 value로 업데이트 됩니다.
만약 조회 작업이 주를 이룬다면, 이 구조를 채택해 성능을 향상시킬 수 있습니다.